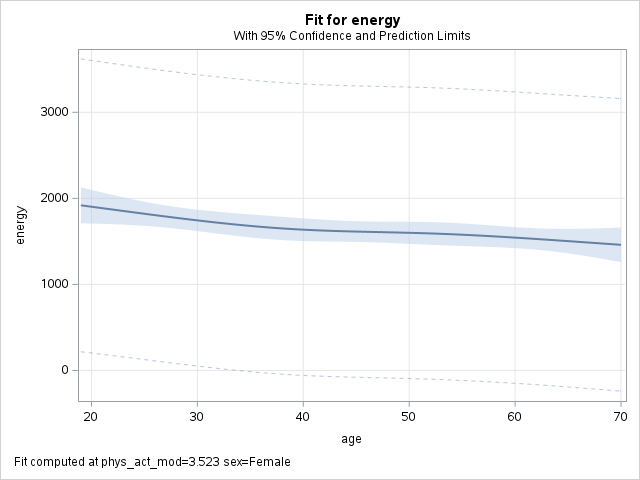
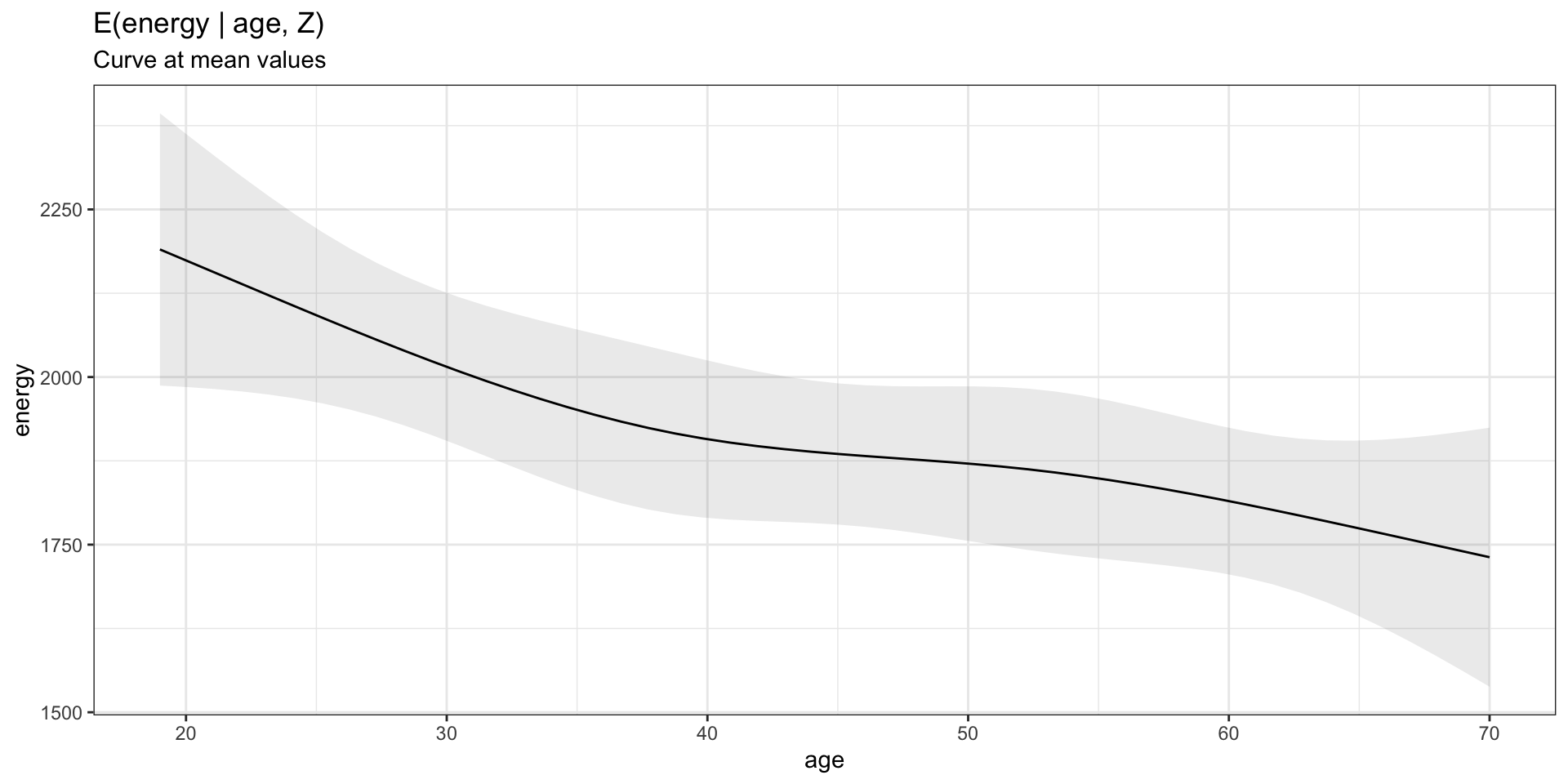
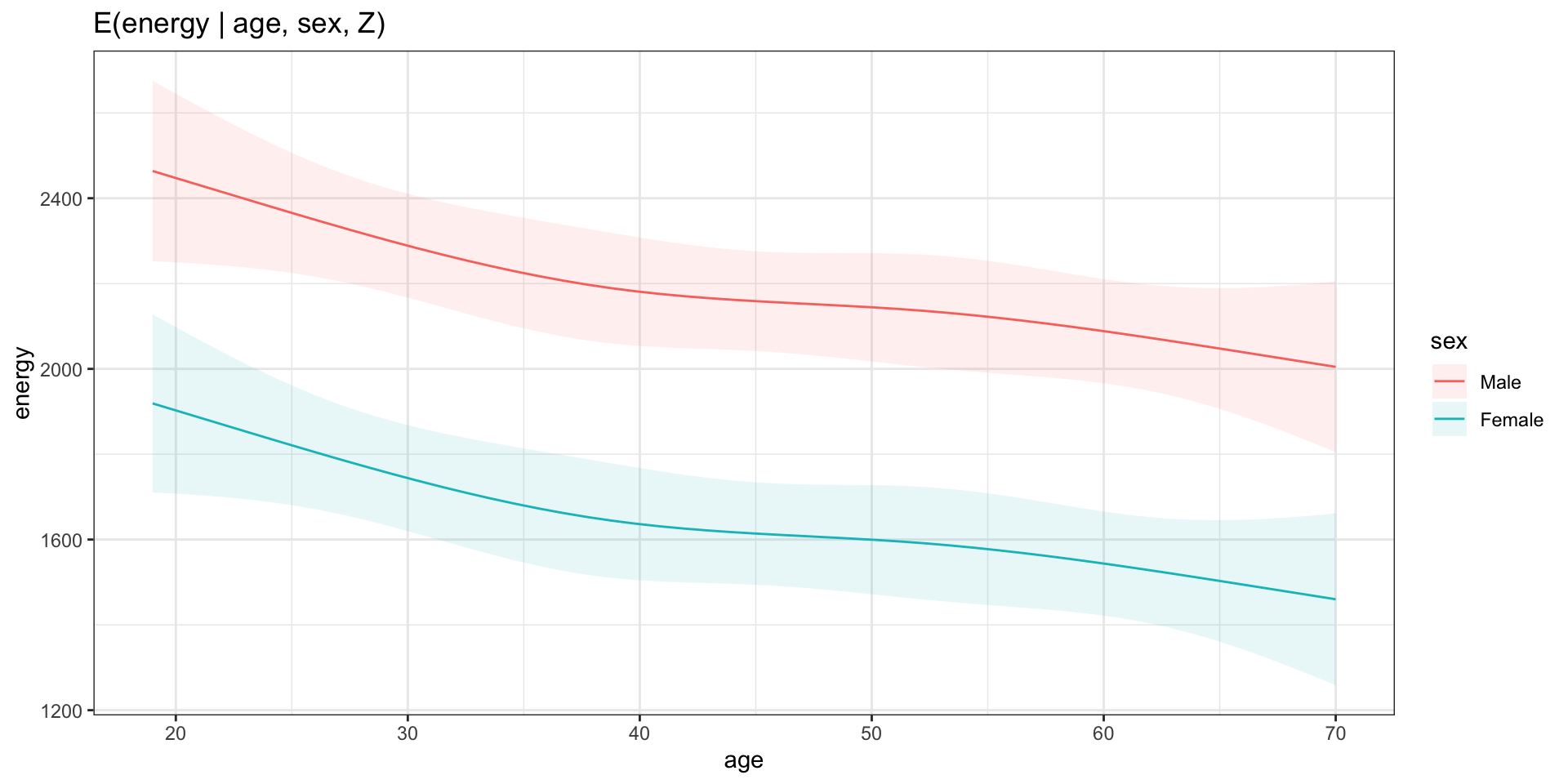
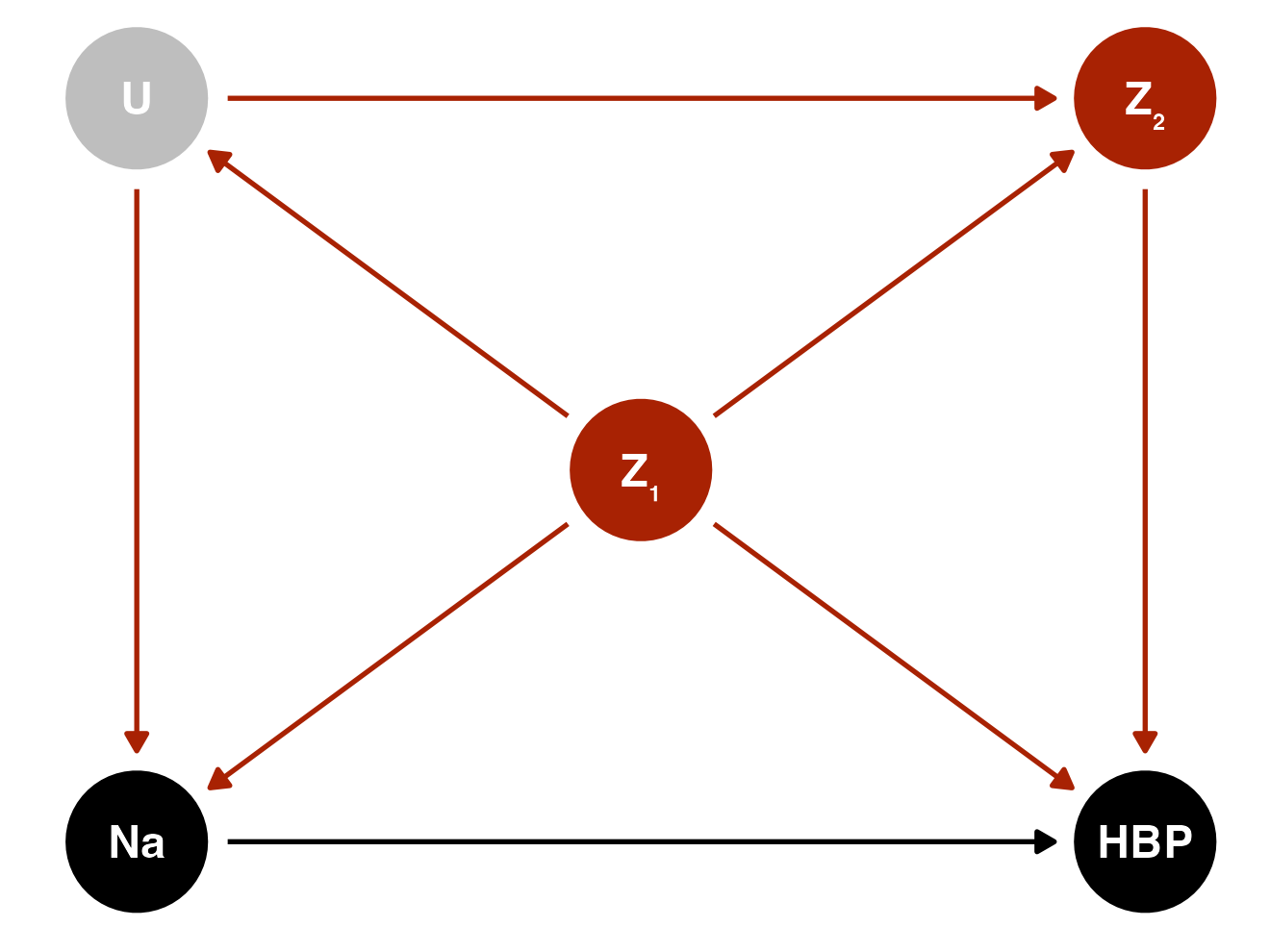
For descriptive purpose, we wish to estimate self-reported energy intakes according to age (years), sex and moderate/vigorous physical activity (hours/week).
Model (estimator)\(\text{Energy}_i=\beta_0 + \beta_1\text{age} + \beta_2\text{female} + \beta_3\text{phys. act.} +\epsilon_i\)
Code
# Preferable to "factorize" before modelling final$sex <-factor(final$sex,levels =c("Male","Female"),labels =c("Male","Female"))# actual model lm1 <-glm(energy ~ age + sex + phys_act_mod,family =gaussian(link="identity"),data = final)
SAS equivalent:
Code
proc genmod data=final ;class sex;model energy = age sex phys_act_mod / dist=normal link=identity ;run
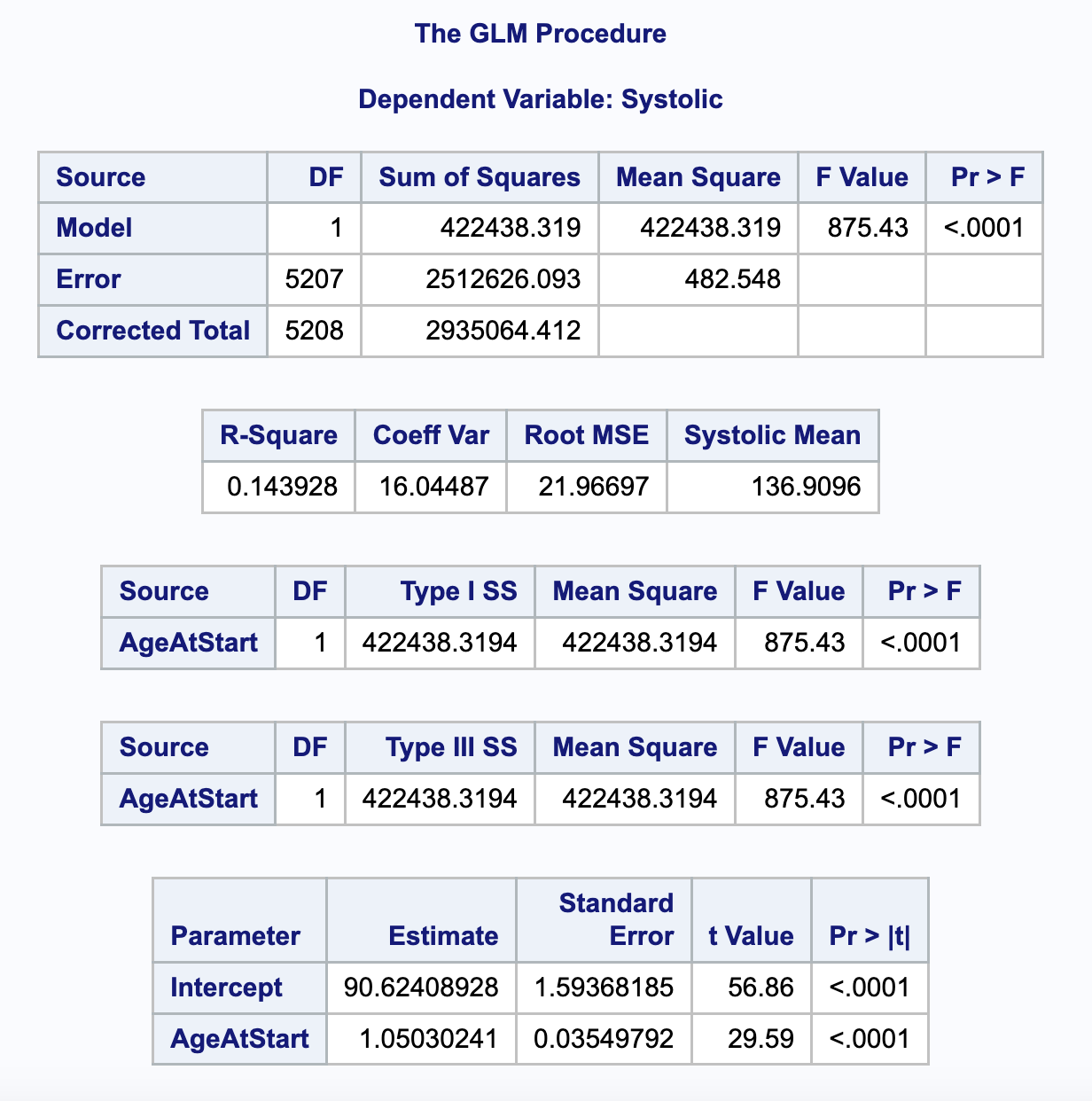
Model summary
What can we say based on this output?
Call: glm(formula = energy ~ age + sex + phys_act_mod, family = gaussian(link = "identity"),
data = final)
Coefficients:
(Intercept) age sexFemale phys_act_mod
2492.535 -7.477 -539.742 21.046
Degrees of Freedom: 997 Total (i.e. Null); 994 Residual
(2 observations deleted due to missingness)
Null Deviance: 835200000
Residual Deviance: 736100000 AIC: 16330
Exploring parameters: overview
Helpful package to assess coefficients and generate standard output:
broom::tidy(model)
parameters::parameters(model)
gtsummary::tbl_regression()
SAS equivalent: ods output <...>; (see procedure documentation or use ods trace on;)
Exploring parameters: example
Code
gtsummary::tbl_regression(lm1)
Characteristic
Beta
95% CI1
p-value
Age, years
-7.5
-11, -3.7
<0.001
sex
Male
—
—
Female
-540
-648, -431
<0.001
Moderate or vigorous physical activity, hours/week
21
7.9, 34
0.002
1 CI = Confidence Interval
Model assumptions: overview
Linear regression models have 4 key assumptions.
Independence;
Homoscedasticity: to verify;
Normality: to verify;
Linearity: to verify.
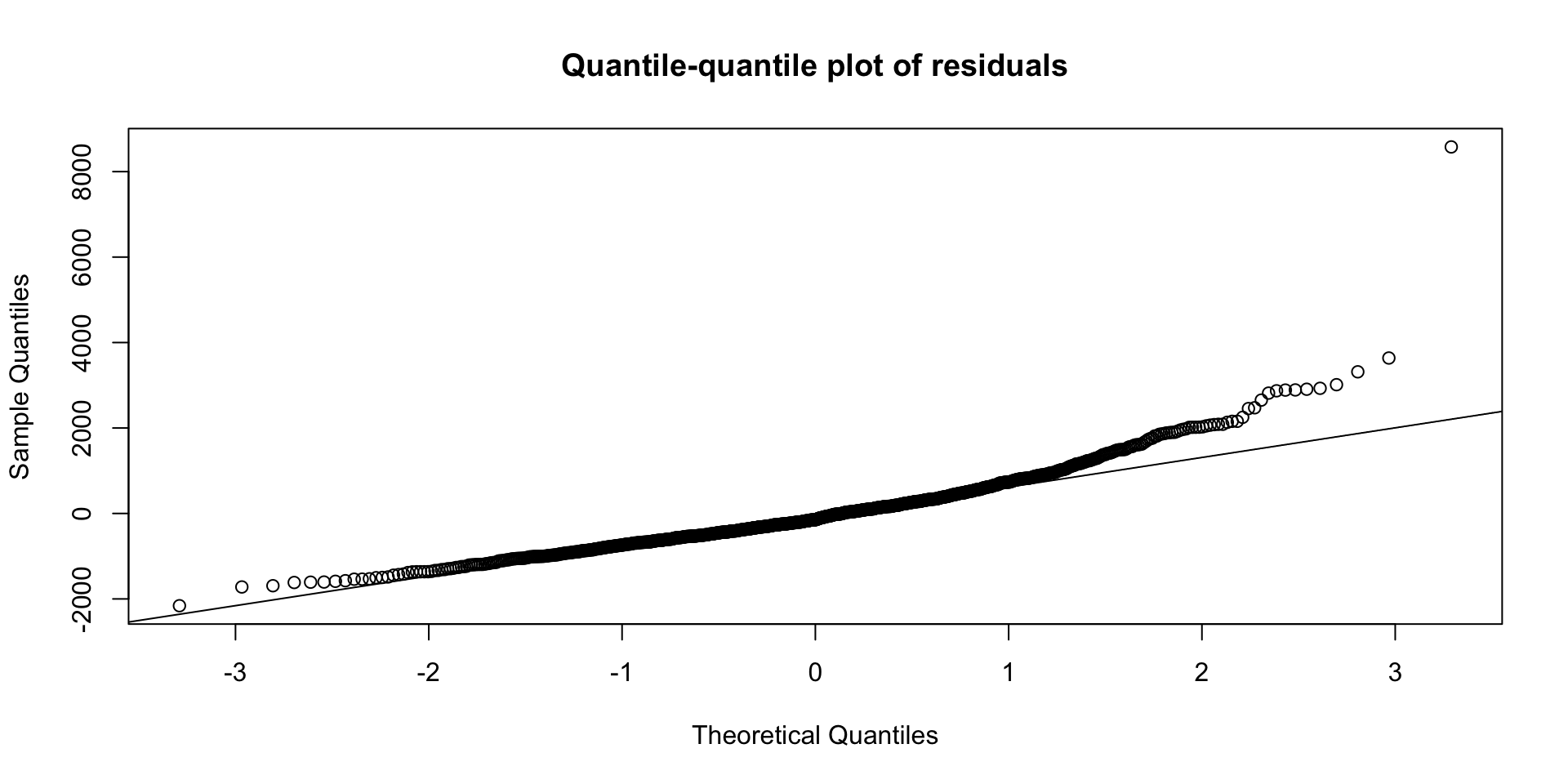
Model assumptions: example
To calculate model errors (residuals): residuals(lm1)
Code
qqnorm(residuals(lm1), main="Quantile-quantile plot of residuals")qqline(residuals(lm1))
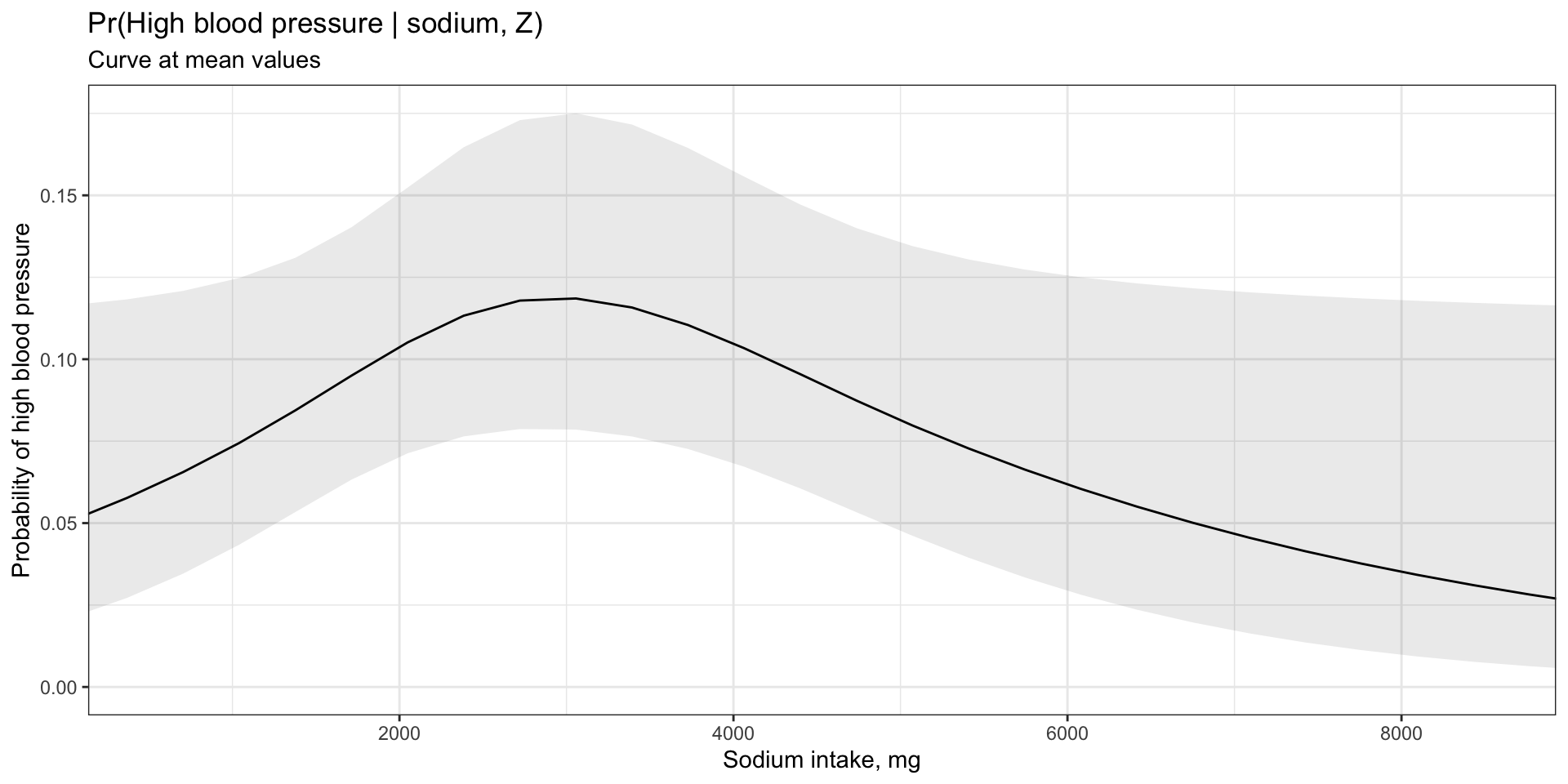
What can we say about this graph?
Model fine-tuning
Independence: assumed by design;
Homoscedasticity: log transformation of energy
Normality: log transformation of energy
Linearity: restricted cubic spline transformation
Of note, log transformation not shown here for simplicity.
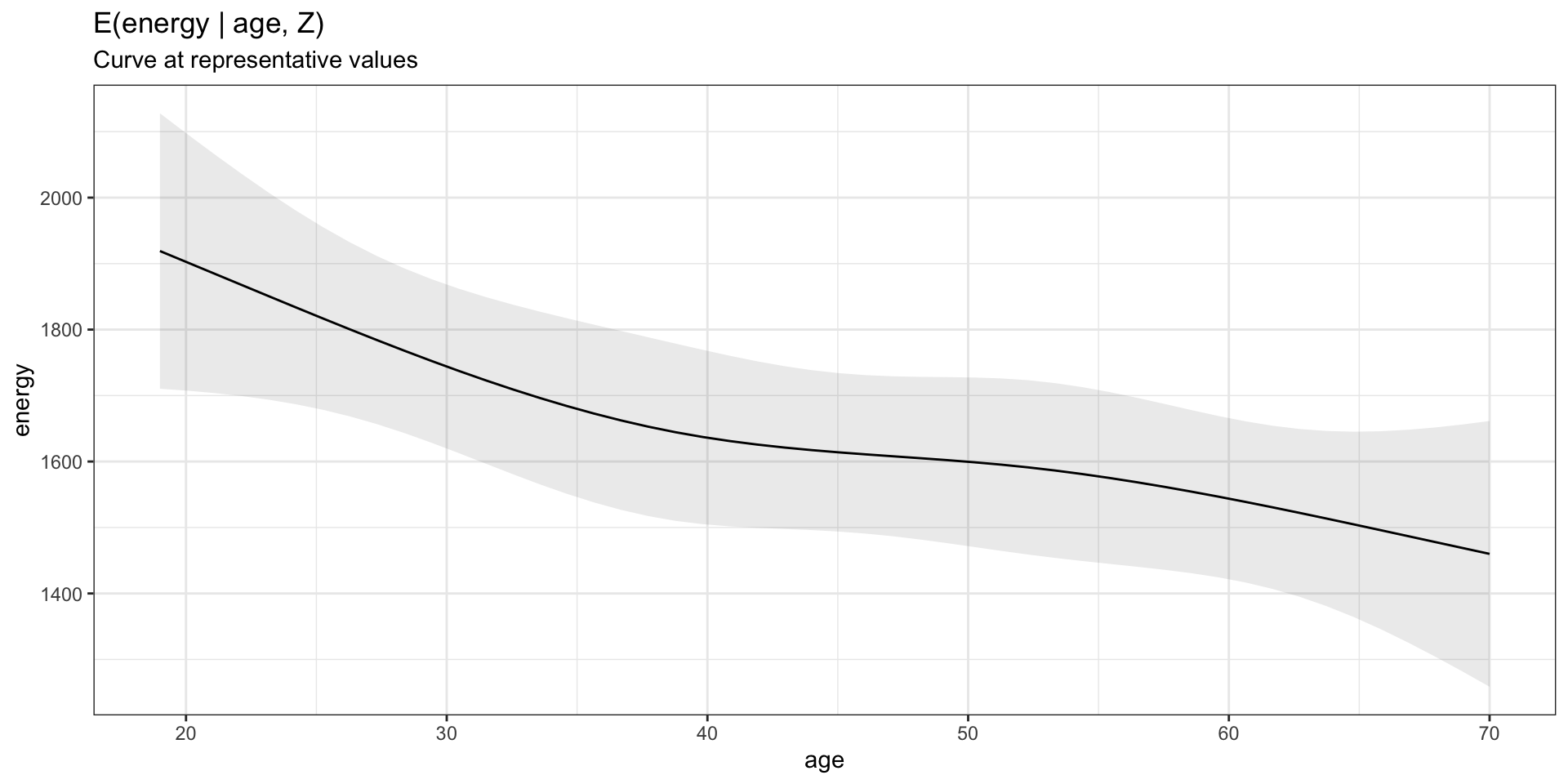
Revised model
Specify Restricted Cubic Spline (RCS) transformation with the rms package.
Term Value Mean Pr(>|z|) 2.5 % 97.5 %
sex Male 2157 <0.001 2040 2274
sex Female 1612 <0.001 1493 1732
Results averaged over levels of: sex
Columns: rowid, term, value, sex, estimate, p.value, conf.low, conf.high, age, energy, phys_act_mod, wts
# recode categorical covariatesfinal <- final |> dplyr::mutate(# education: university vs. elseedu_4 =ifelse(education==4,1,0),# smoking: daily or occasional smoker vs. elsesmk_1 =ifelse(smoking %in%c(1,2),1,0) )# confirm recodingwith(final,table(edu_4,education))
Harrell, F. E. 2015. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis. Book. Springer International Publishing. https://books.google.ca/books?id=kfHrF-bVcvQC.
Norton, E. C., B. E. Dowd, and M. L. Maciejewski. 2019. “Marginal Effects-Quantifying the Effect of Changes in Risk Factors in Logistic Regression Models.” Journal Article. JAMA 321 (13): 1304–5. https://doi.org/10.1001/jama.2019.1954.